
 起点课堂会员权益
起点课堂会员权益功能设计之搜索背后的逻辑处理
搜索应该是我们日常使用最多的一项功能了。在产品设计中,搜索也是非常重要的,但其逻辑又相对比较复杂。这篇文章,作者带我们来梳理一下搜索的产品逻辑。

搜索场景无处不在,主要包括搜索引擎的搜索、平台商品搜索、平台文章搜索,还有一些数据库的简单搜索。但万变不离其宗,接下来主要介绍一下以商品/文章类搜索等为主的搜索流程及细节。
一、搜索流程
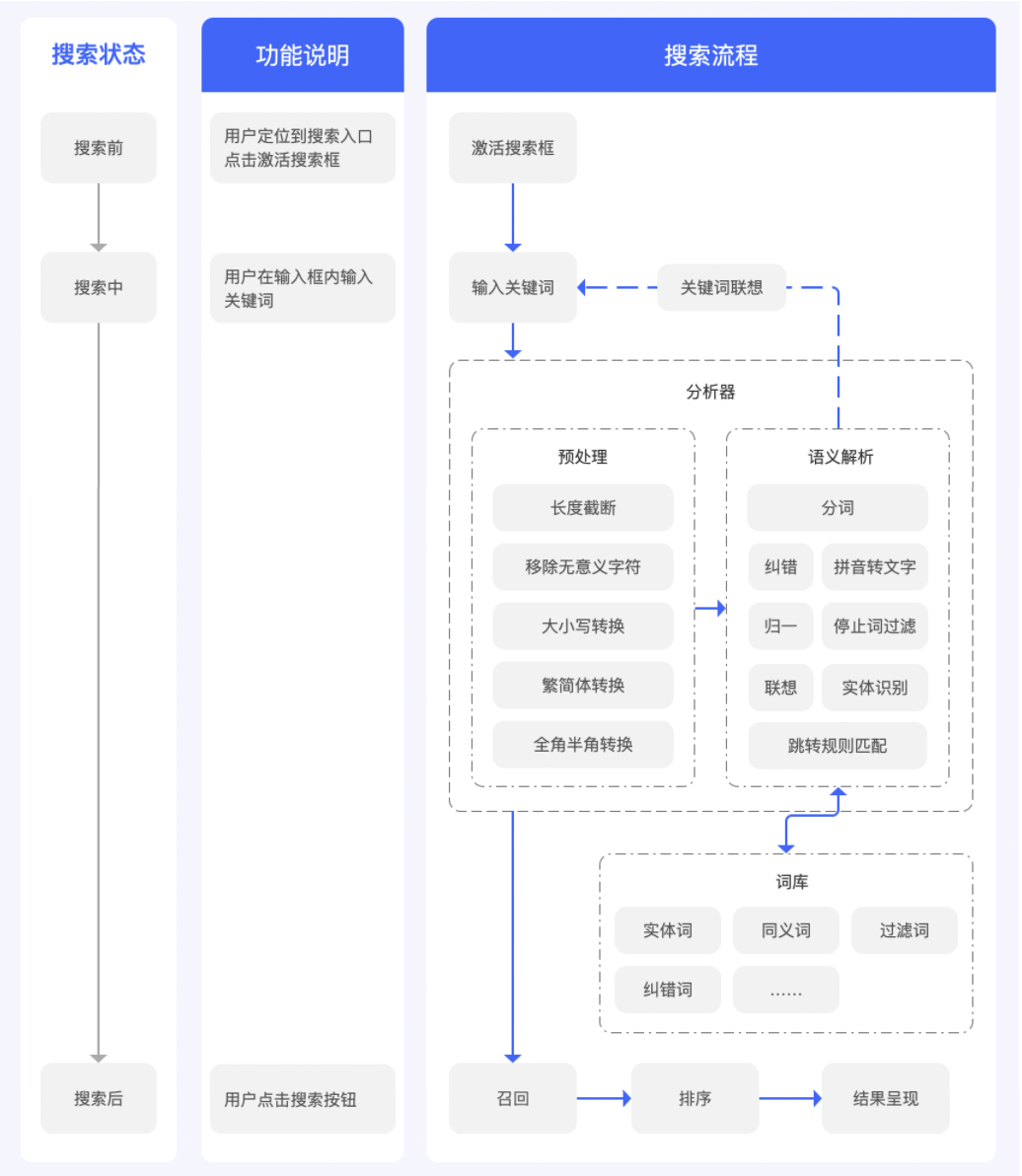
二、搜索入口
移动端的搜索入口常见于以下4种模式
1、位于底部导航栏
适用于搜索需求极高或者搜索是核心流量入口的产品,如微博、花瓣等

2、位于页面顶部
适用于搜索是重要流量入口的产品,如淘宝、知乎等。并会通过频繁变化的占位词引导搜索

3、放大镜搜索图标
适用于当前页搜索功能并非高频操作的页面,将顶部、底部导航栏等位置让渡给更重要的功能,搜索功能弱化为icon图标,如知乎的关注页、招行的财富页等

4、隐藏式搜索入口
不常用。目前仅在手机系统交互中出现,比如iPhone的下拉搜索
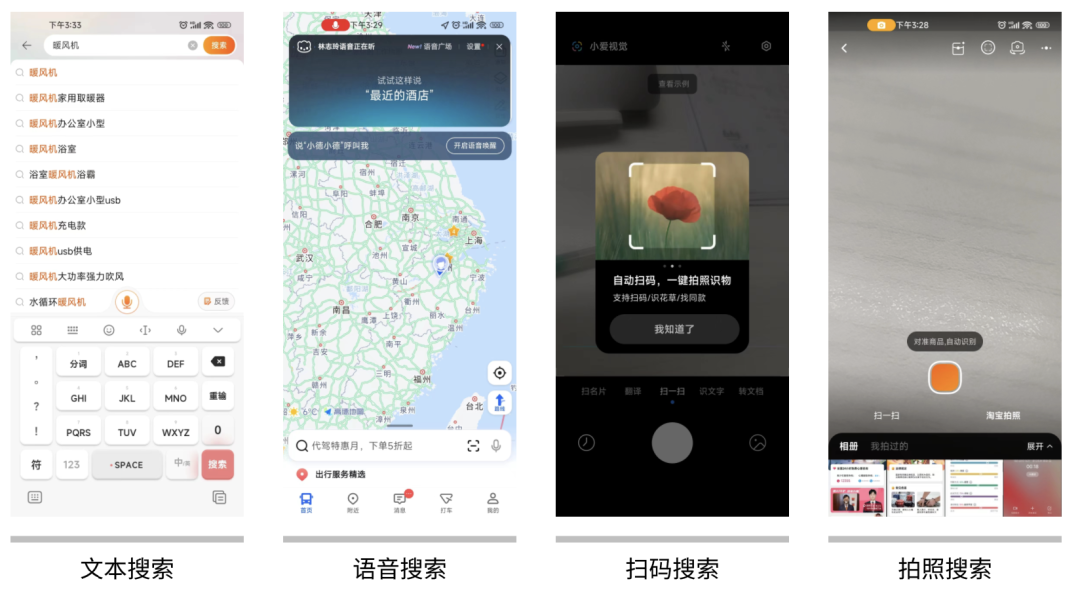
三、搜索方式
常见的搜索方式主要包括文本搜索、语音搜索、扫码搜索、拍照搜索
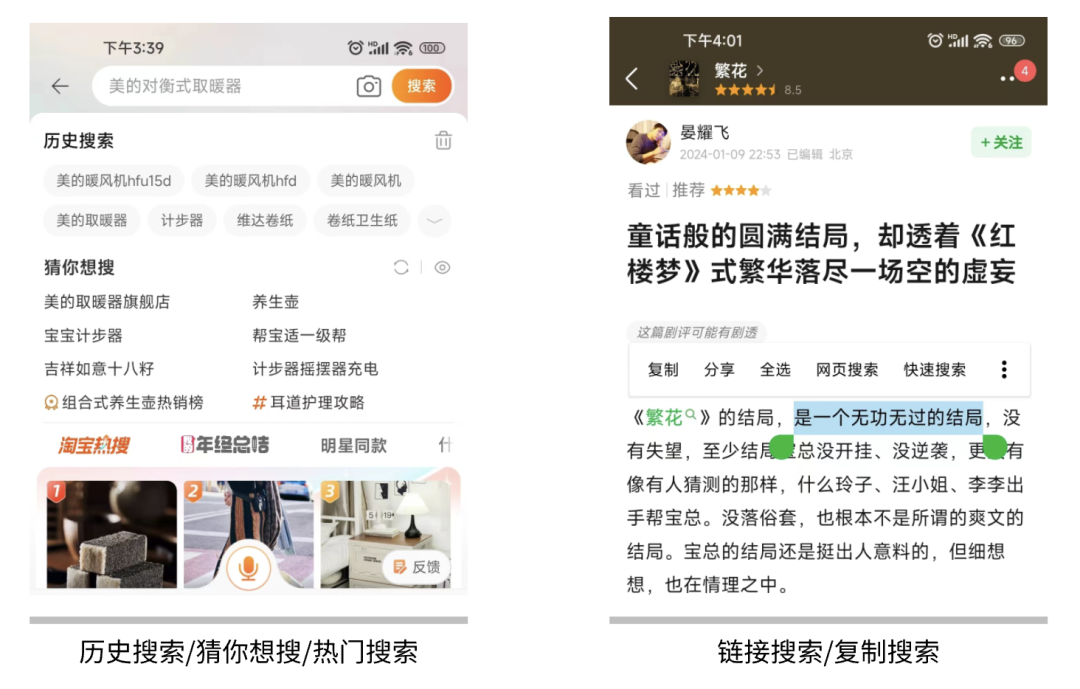
为了提高搜索的便捷性和转化率,又衍生出历史搜索、猜你想搜、热门搜索、链接搜索、复制搜索等
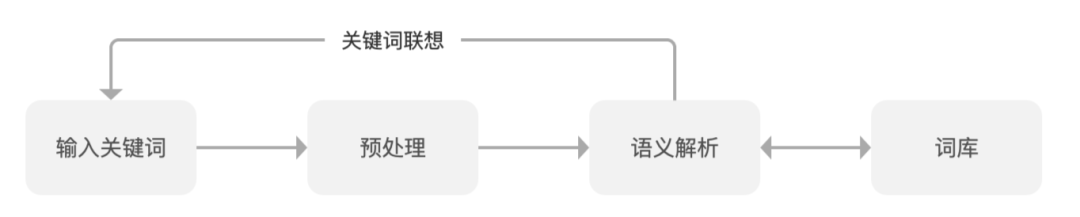
四、分析器
用户输错了怎么办?用户输入的这个关键词究竟是什么含义?分析器的作用就是对用户输入的关键词进行预处理、语义解析,实现对关键词的联想和优化系统对用户输入内容的理解。
1、预处理
1)长度截断:为了避免超长字符对分词搜索的压力,一般会限制关键词的字数,比如百度搜索控制在38个汉字以内
2)移除无意义字符:包括emoji、特殊符号、颜文字等
3)格式转换:包括大小写转换、繁简体转换、全角半角转换等
2、语义解析
1)分词:根据分词词库将关键词进行拆分,如果输入的是词库未收录的关键词,可能就无法检索到关键内容了(除非完全拆成单字)

2)纠错:根据纠错词对用户输入的可能错误的关键词进行纠正,主要包括以下两种
① Non-word-Error:不存在数据库的错误字符
- 数字错误:2202→2022
- 英文错误:fght→fight
- 拼音错误:ping’pag→乒乓
- 首字母简拼:cpjl→产品经理
- 混合错误:cha品ji理→产品经理
② Real-word-Error:由多个汉字组成的错误语句(拼写正确,但结合上下文语境表意错误)
- 漏字:产品理→产品经理
- 多字:产品经理理→产品经理
- 颠倒:经理产品→产品经理
- 同谐音:产品经历→产品经理
- 模糊音:产品尽力→产品经理
- 形近字:产品经哩→产品经理
当然,具体的纠错效果跟纠错词的可信度有关,可信度高时,会直接使用纠错词查询(提供原词备选),可信度低时,还是会使用原词查询

3)拼音转文字:比如将“kangshifu方便面”转换成“康师傅方便面”
4)归一:中文中很多词的含义是一致的,因此会通过近义词词库将不同的输入理解成相同的含义,比如“价格”、“售价”、“多少钱”等表达的都是价格的含义
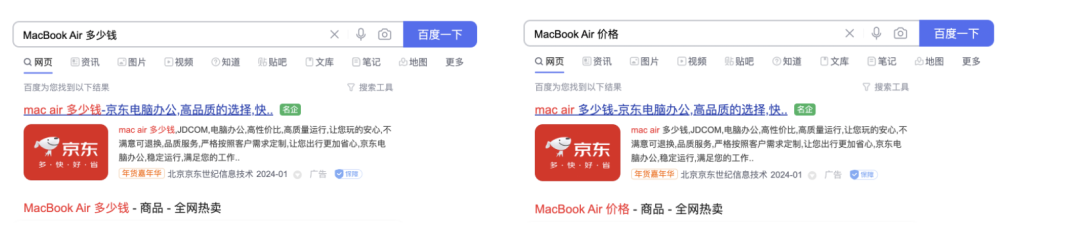
5)停止词过滤:比如会将非法词、敏感词、指定的无意义词汇过滤掉
6)联想:调用关键词统计接口,实时获取排名靠前的数据。具体的query候选集的生成策略还会受用户历史记录、热搜记录和运营人工干预的影响,以便帮助用户尽快找到他们想要的内容
7)实体识别:借助实体词库,对输入的关键词进行实体含义的分析,比如将【康师傅红烧牛肉面】解析为【Brand:康师傅;Taste:红烧;SPU &CATEGORY:方便面】。当然,不同行业不同领域都会有自己的词库,差别比较大,因此词库一般都是不互通的
8)跳转规则匹配:比如输入到某个特定关键词时,跳转到特定的页面,比如某品牌的官网等等,且通常这种跳转是有时效限制的
五、召回
召回指的是将解析后的关键词与数据库文档进行匹配的过程。这个过程需要用到后端的倒排索引技术(构建单词与文档的关联关系)。一般来说,倒排索引建设得越合理,查询效率就越高。

六、排序
同样是在商城中搜索“水”,你觉得以下哪种排序更好?
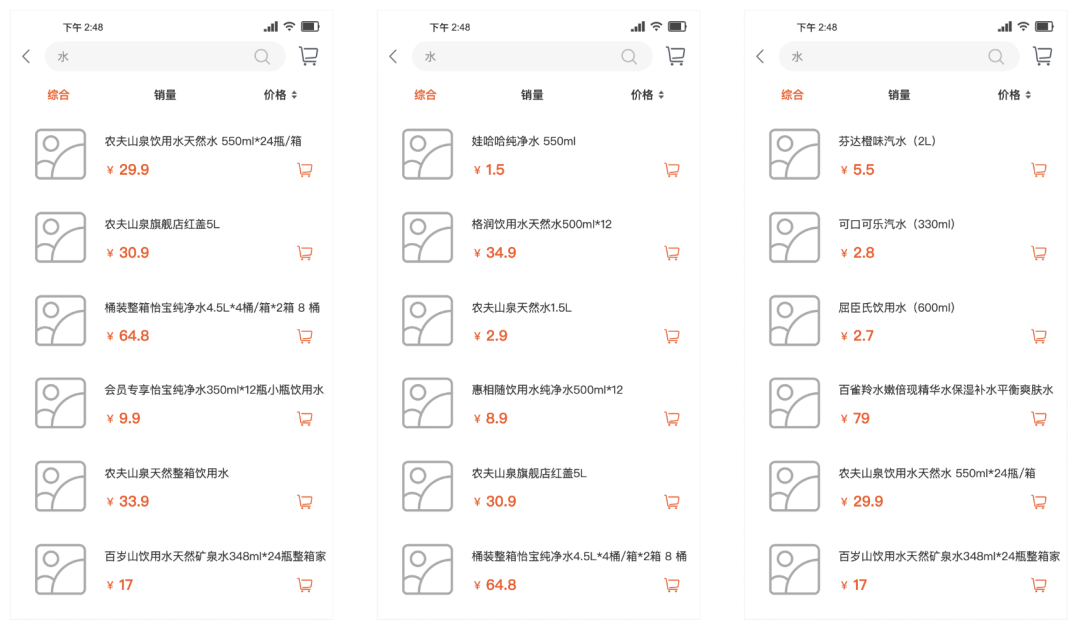
结论:
- 左图:好,大众熟知的产品排在最前面。
- 中图:中,小众产品排在最前面。
- 右图:差,将仅包含“水”的汽水、爽肤水等排在前面。
下面以电商为例进行排序策略的介绍
1、粗排
考虑召回结果与query之间的相关性,并按照相关性模型进行打分,最终根据相关性从高到低排序。如果两个召回结果的得分一致,则按ES索引自行排序,因此每次搜索结果都有可能不同。
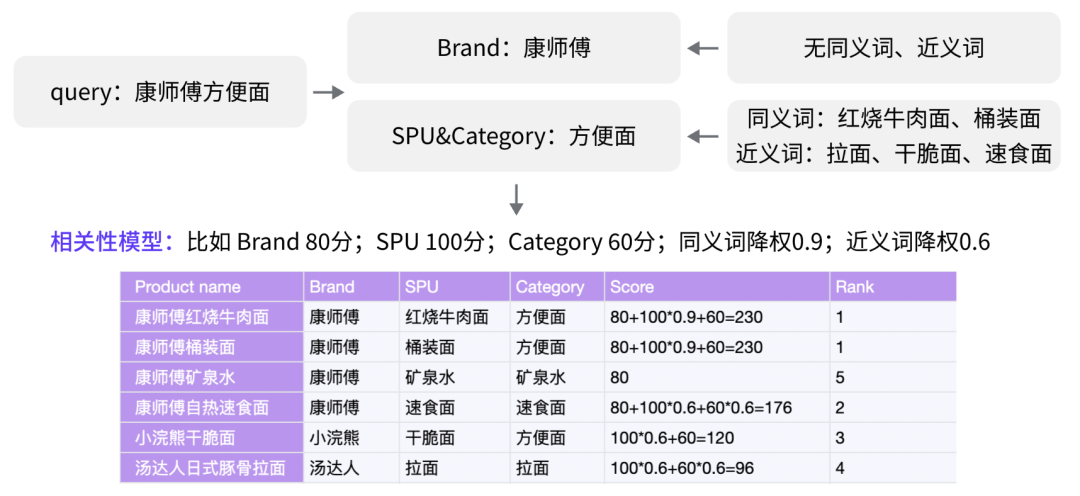
2、精排
在粗排基础上,考虑销量、收藏、点击、加购、促销等业务因素对排序的影响。
比如销量收藏高的靠前,比如最近门店正在跟某个品牌搞合作,则这个品牌靠前等等。
但是,这些因素要怎么量化呢?比如销量,不同商品之间无法直接比较个数,统计周期、门店等等也会对统计造成影响。所以这里就需要引入一个归一化公式,计算出一个业务因素的调整系数。比如初始销量是50,系数是0.5,那么最终得分是25分。再将此分数与相关性得分相加,得到最终的综合得分。
归一化公式参考:(商品订单数 — 门店最少的商品订单数 )/ (门店最高的商品订单数 — 门店最少的商品订单数 )
3、排序模型
粗排和精排都是建立在“业务规则”的基础上,利用的是专家对市场的了解;而排序模型则是利用机器学习、深度学习等技术构造千人千面的模型。不过这种方式只适用于用户数据量比较大的平台。
七、结果呈现
1、搜索结果的清晰呈现
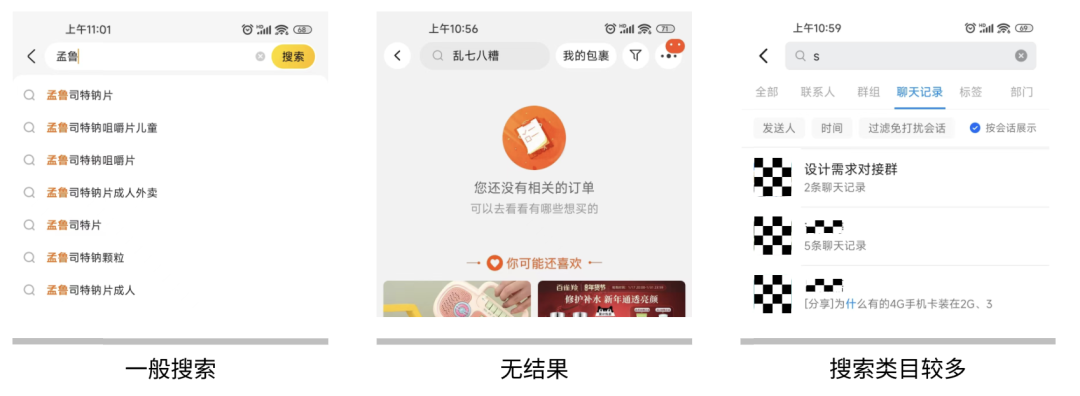
2、个性化设计

作者:D.lemon,公众号:柠檬的产品小记
本文由 @D.lemon 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。















感谢柠檬姐,非常好的干货
很棒!挖掘的很深度 关注了
赞个,学习了
很棒的文章,言简意赅的概述了搜索产品背后的逻辑,点赞