

关键词是代表文章重要内容的一组词,对文本聚类、分类、自动摘要等起着重要的作用。关键词提取算法一般分为有监督和无监督两类。有监督的关键词提取方法主要是通过分类的方式进行,通过构建一个较为丰富和完善的词表,然后通过判断每个文档与词表中每个词的匹配程度,以类似打标签的方式,达到关键词提取的效果。有监督的方法能够获取到较高的精度,缺点是需要大批量的标注数据,人工成本过高。
相对于有监督的方法而言,无监督的方法对数据的要求就低多了,这类算法在关键词提取领域的应用更受到大家的青睐。目前比较常用的无监督关键词提取算法有:TF-IDF 算法、TextRank 算法、主题模型算法(LSA、LSI、LDA)等。下面主要介绍一下 TF-IDF 算法。

TF-IDF 算法
TF-IDF 算法(Term Frequency-Inverse Document Frequency)是一种基于统计的计算方法,常用于评估在一个文档集中一个词对某份文档的重要程度。一个词对文档越重要,越可能是文档的关键词,人们常将 TF-IDF 算法应用于关键词提取中。TF-IDF 算法由两部分组成:TF 算法和 IDF 算法。
TF 算法是统计一个词在一篇文档当中出现的次数,基本思想是:一个词在文档中出现的次数越多,则其对文档的表达能力越强。IDF 算法是统计一个词出现在多少个文档当中,基本思想是:一个词在越少的文档中出现,则其对文档的区分能力越强。TF 算法的计算公式如下:
tf(word) = (word 在文档中出现的次数) / (文档总词数)
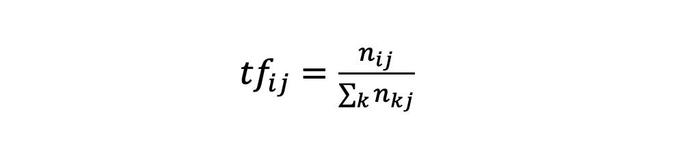
其中 nij 表示词 i 在文档 j 中出现的频次,但如果仅用频次来表示,长文本中的词出现频次高的概率会更大,这会影响到不同文档之间关键词权值的比较,所以一般进行归一化,分母部分就是统计文档中每个词出现次数的总和,也就是文档的总次数。
IDF 算法的计算公式如下:
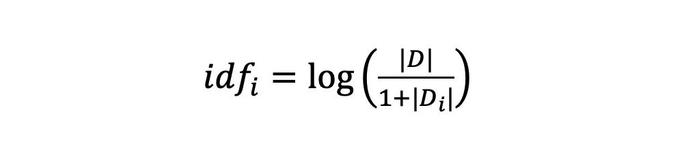
|D| 为文档集中总文档数,|Di| 为文档集中出现词 i 的文档数量,分母加 1 是采用了拉普拉斯平滑,避免有部分新的词没有在语料库中出现过而导致分母为零的情况,增强算法的健壮性。
TF-IDF 算法是 TF 算法和 IDF 算法的综合使用,其计算公式如下:
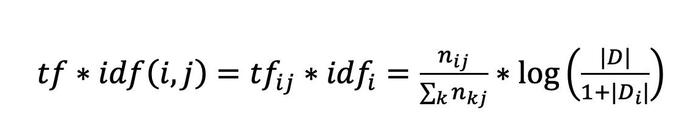
除了传统的 TF-IDF 算法之外,TF-IDF 算法也有很多变种的加权方法。传统的 TF-IDF 算法中,仅考虑了词的两个统计信息(出现频次、在多少个文档出现),对文本的信息利用程度相对较少。除了这两个统计信息外,在一个文本中还有许多信息能对关键词的提取起到很好的指导作用,例如:每个词的词性、出现的位置等。在某些特定的场景中,如在传统的 TF-IDF 算法基础上,加上这些辅助信息,能对关键词提取的效果起到很好的提高作用。
在文本中,名词作为一种定义现实实体的词,带有更多的关键信息,如在关键词提取过程中,对名词赋予更高的权重,能使提取出来的关键词更合理。此外,在某些场景中,文本的起始段落和末尾段落比起其他部分的文本更重要,如对出现在这些位置的词赋予更高的权重,也能提高关键词的提取效果。
作者:Kevin Tao
知乎号:Kevin陶民泽
备注:转载请注明出处。
如发现错误,欢迎留言指正。













